

Intro
It’s been a while since I wanted to write an article about something both interesting and useful in the development field.
It’s been almost 4 years since I started developing games and game engines. I’ve always wanted to conquer the magic of multithreaded programming and its effective usage. I started digging in this direction about 2 years ago, read a decent amount of articles on this topic. Yet, I couldn’t find anything extraterrestrial or innovative, except for this awesome Wikipedia article about the core of the idTech 5 engine. This article turned my understanding of multithreaded programming upside down, both for games and in general. E.g. basically pretty much every algorithm can be accelerated, be it physics simulation, preparing game objects for rendering, or even computing Voronoi diagram.
In the given article I am going to discuss the main types of multithreading that I managed to separate, also their strong and weak sides.
Ordinary Multithreading
Ordinary multithreading is being used pretty much everywhere. It has been applied in the first version of our studio’s own game engine, it can also be found in Cocos So what does this concept actually mean and where is it used most commonly? Most often, it is used to free up the main thread from simple yet heavy weight operations like HTTP-requests, decoding of video and audio stream, etc.
Developers simply open the new thread that shuts down after the operation is complete. Best case scenario is that such operations are going to queue, and the thread closes only after operations are complete. This solution is really simple and also happens to be cross-platform. Yet it is replete in variety of blocking synchronization mechanisms.
Occasionally, I come across people who rely on Lock-free data structure when trying to overcome those mechanisms. What they don’t understand is that Lock-free is basically a hyped up brand. That is because all Lock-free structures rely on the loop that tries to capture the required data. In this case, the loop still kind of acts like a lock, even though it is supposedly lock-free. Although its behavior is more similar to spinlock than mutex. It is questionable whether using Lock-free is worth using in real tasks.
Correct Multithreading
I learnt what correct multithreading is when I encountered GCD (Grand Central Dispatch) for iOS. I personally liked it due to its simplicity, absence of any obvious locks, and mostly due to possibility to add it to any queue. It is great because the system does not have to constantly open and close the threads. Additionally, GCD allowed to solve any tasks that ordinary multithreading dealt with.
So I decided to use this approach. Yet WinApi didn’t have any similar features, and I had to build it on my own. The solution was simple to implement. It uses several high-speed queues for tasks that are processed by multiple threads instead of standard locks.
There were no problems associated with such queue in WinApi because it uses IOCP (Input Output Completion Port).
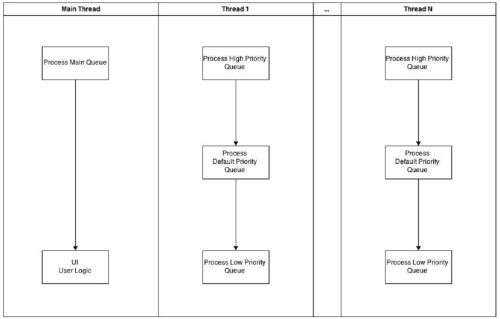
Ideal Multithreading
Understanding how GCD works and availability of the ultrafast queue opened a concept of ideal multithreading to me. How does it work? A large task is broken into smaller elements that are processed by several threads simultaneously. Such approach allows to save time of completing the task. Let’s explore the table:
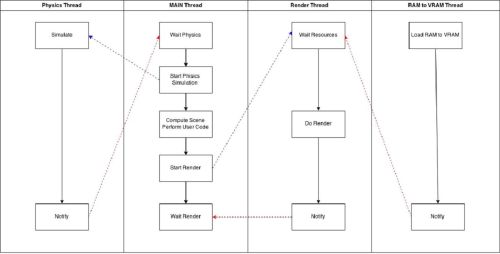
If separate one loop tick of the game into smaller tasks, then we can get the system that is described above. The main idea is that RamToVRam thread loads data into GPU memory while main thread is working. By the time the main thread is done processing, all necessary data can already be loaded into VRam. It can save time on processing the frame. The worst case scenario is that the speed of such system would equal to single threaded system.
If we can split a big task into smaller tasks, what is the obstacle to do the same trick with any other algorithm? Right, there isn’t any! For instance, it is possible to process these tasks in background threads:
- Computing particle systems
- Calculating coefficients for Voronoi diagram points
- Calculating object matrix transformation
- Tons of other tasks where there is lots of data.
The only drawback of such approach is that a developer has to manually control queues and threads. Still, for certain tasks GCD would be more suitable.
Absolute Multithreading
Absolute multithreading flows out of the previous option, but it calls for GPU power to be implemented. A long time ago I used to mistakenly think that calculating physics using GPU is a waste of time and resources. I didn’t understand how a less powerful device can speed up anything. However, after a more careful investigation I realized that GPU can’t solve one heavy task, but it can solve many simple tasks simultaneously. If you need to multiply tons of matrix or transform many points, feel safe to delegate these tasks to GPU, it will deal with them much faster than CPU using SSE instructions.

Final Word
If anyone is interested in the given theme, there is a more detailed follow-up post coming soon.
Master of Code designs, builds, and launches exceptional mobile, web, and conversational experiences.


